Understanding Components
Note
The goal of this page is to help you understand the apps or components available throughdfuseeos start, with their respective role and interaction.
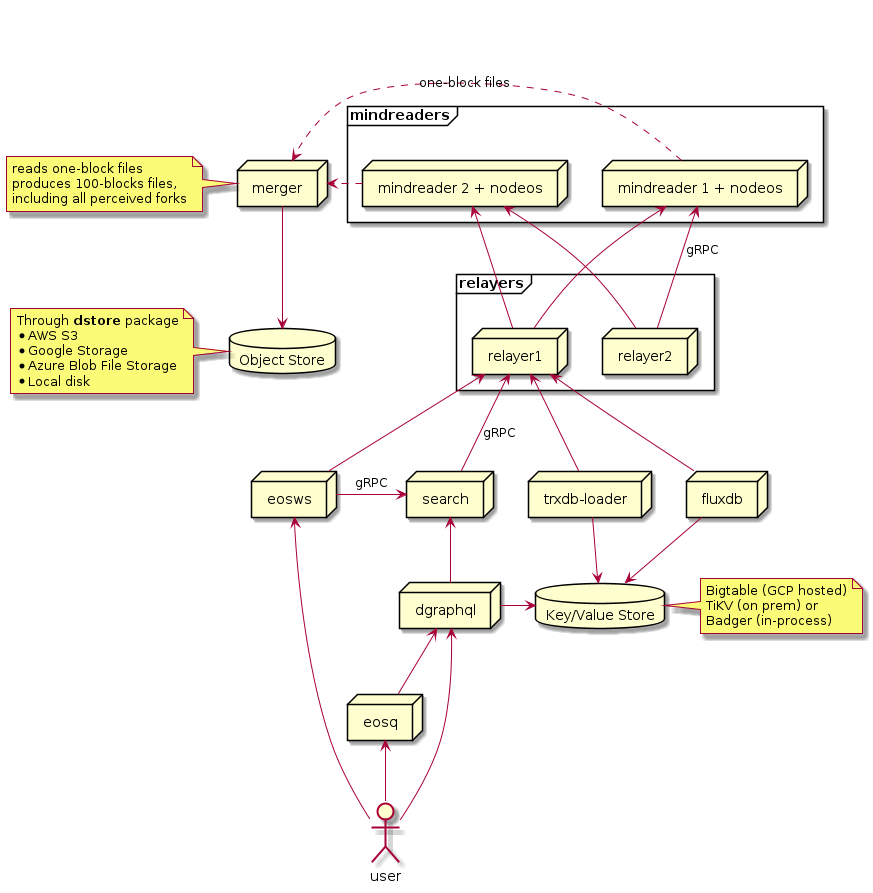
General Architecture Diagram
Video Series
To help you better understand certain components and dfuse at a higher level, our CTO recorded engaging video overviews. If you’re looking for written information, keep scrolling!
dfuse for EOSIO Architecture Series
- General Overview
- deepmind & the dfuse Data Model
- manageos & mindreader
- bstream part 1
- bstream part 2
- High Availability with Relayers, Merger
- pitreos
Webinars
Components Description
mindreader
Description: The mindreader processes uses the node-manager library to run a blockchain node (nodeos) instance as a sub-process, and read data produced therein.
This is the primal source of all data that will flow in all systems
High Availability considerations: You will want more than one mindreader if you want to ensure blocks always flow through your system. dfuse is designed to deduplicate any mindreader data produced that would be identical (when two mindreader instances execute the same block), and also to aggregate any forked blocks that would be seen by one mindreader, and not by another one. See the merger for details.
mindreader-stdin
Description: mindreader-stdin replaces mindreader in situations where you want to manually manage backup/recovery, chain restoration, and you don’t want the other benefits offered by the node-manager software.
High Availability considerations: It has the same HA properties as mindreader.
relayer
Description: The relayer serves executed block data to most other components.
It feeds from all mindreader nodes available (in order to get a complete view of all possible forks)
Its role is to fan-out that block information.
The relayer serves its block data through a streaming gRPC interface called BlockStream::Blocks (defined here). It is the same interface that mindreader exposes to the relayers.
NOTE: recent relayer can have filters applied
High Availability considerations: Relayers feed from all of the mindreader nodes, to get a complete view of all possible forks.
merger
Description: The merger collects one-block files written by one or more mindreaders, into a one-block object store, and merges them to produce merged blocks files (or 100-blocks files).
One core feature of the merger is the capacity to merge all forks visited by any backing mindreader node.
The merged block files are produced once the whole 100 blocks are collected, and after we’re relatively sure no more forks will occur (bstream’s ForkableHandler supports seeing fork data in future merged blocks files anyway).
Detailed Behavior
- On boot, without merged-seen.gob file, it finds the last merged-block on storage and starts at the next bundle.
- On boot, with merged-seen.gob file, the merger will try to start where it left off.
- It gathers one-block-files and puts them together inside a bundle
- The bundle is written when the first block of the next bundle is older than 25 seconds.
- The bundle is only written when it contains at least one fully-linked segment of 100 blocks.
- The merger keeps a list of all seen(merged) blocks in the last {merger-max-fixable-fork}
- “seen” blocks are blocks that we have either merged ourselves, or discovered by loading a bundle merged by someone else (mindreader)
- The merger will delete one-blocks:
- that are older than {merger-max-fixable-fork}, or
- that have been seen(merged)
- If the merger cannot complete a bundle (missing blocks, or hole…) it looks at the destination storage to see if the merged block already exists. If it does, it loads the blocks in there to fill its seen-blocks cache and continues to next bundle.
- Any one-block-file that was not included in previous bundle will be included in next ones. (ex: bundle 500 might include block 429)
- blocks older than {merger-max-fixable-fork} will, instead, be deleted.
High Availability considerations: This component is needed when you want highly available mindreader nodes. You only need one of these, because the whole system can survive downtime from the merger, and it only produces files from time to time anyway.
Systems in need of blocks, when they start, will usually connect to relayers, get real-time blocks and go back to merged block files only when the relayer can’t satify the range. If relayers provide 200-300 blocks in RAM, then you have that time for the merger to be down, to sustain restarts from other components. Once the other components are live, in general, they won’t read from merged block files.
merged-filter
Description: The merged-filter is an optional process that will ingest merged block files, filter them on-the-fly, and write those filtered block files back to a second destination storage.
Other components can then be pointed to that Object Storage location, and will therefore consume less RAM, because they’ll process already filtered merged blocks files.
This is useful in filtered deployments, backed by an unfiltered deployment.
High Availability considerations: Similar to those of the merger, as they consume the same files, and produce the same sort of files (merged blocks files).
statedb
Description: statedb is a special-purpose database to provide state snapshots of all blockchain state, at any block height.
statedb has two modes of operation (enabled alone or in combination through command-line flags):
injectmode, which writes to thekvdbstoreservermode, which receives requests from end users and serves them. It also is connected to thekvdbstore, and holds a buffer with recent blocks.
Both components receive blocks from a relayer.
High Availability considerations: The inject mode is stateful and needs to have at most one instance running at any time. The server mode is stateless and needs 2 or more to sustain upgrades/maintenance/crashes.
Simple deployments will have both in one process, in which case you do not want to scale it to more than one, because of the inject mode constraint, which writes transactionally to the backing database.
trxdb-loader
Description: Takes the blockchain data and inserts it into out database instance (BigTable).
High Availability considerations: The system can sustain trxdb-loader being down for some time. Processes have internal buffer to cover their needs during this period.
eosws
Description: EOSIO-specific websocket interface, REST interface, Push guarantee instrumented /v1/chain/push_transaction endpoint, and pass-through to statedb.
High Availability considerations: This process is stateless, and can be scaled up or down for the desired throughput. You want at least 2 to sustain one being down.
dgraphql
Description: dgraphql is a server process serving end-user requests in the GraphQL format. It speaks GraphQL over both HTTP and gRPC. It routes most of its request to the appropriate service. In particular: search-router (for backward/forward searches), statedb server (for state queries), blockmeta (for block by time resolutions), tokenmeta (for token queries).
High Availability considerations: This process is stateless, and can be scaled up or down for the desired throughput. You want at least 2 to sustain one being down.
tokenmeta
Description: The tokenmeta service is a specialized indexer for tokens, holders, and balances. It can provide clean and quick snapshots of that information. It is exposed through dgraphql.
High Availability considerations: This is a stateless deployment, as it bootstraps from statedb, and streams changes from relayers. You will want two or more to ensure zero downtime upgrades.
abicodec
Description: This service is dedicated at decoding and encoding EOSIO binary format back and forth from JSON, using the on-chain ABIs. It can do so at any block height, and is constantly kept in sync with changes from the chain.
On boot, it turns to a search-router to save all eosio::setabi transactions. It keeps a local cache in a dstore location.
High Availability considerations: This process is stateless, and can be scaled up or down for the desired throughput. You want at least 2 to sustain one being down.
eosq
Description: eosq is the web front-end (block explorer) interface to the dfuse APIs. A self-contained https://eos.eosq.eosnation.io
High Availability considerations: This process is stateless, and can be scaled up or down for the desired throughput. You want at least 2 to sustain one being down.
blockmeta
Description: blockmeta is the service that is queried by systems wanting to know the general status of the chain, in terms of head block, irreversible block, block times comparisons, past blocks status of irreversibility, etc.
It does not know much about each block, for instance, it doesn’t keep track of the transaction counts for example. Just enough to help other processes bootstrap themselves (finding their start block, last irreversible block, etc..). It is like a spinal cord of a dfuse deployment.
High Availability considerations: This process is stateless, and can be scaled up or down for the desired throughput. You want at least 2 to sustain one being down.
booter
Description: This is the process that will bootstrap your chain if it detects that it has not been bootstrapped yet. It will kick in if you run node-manager, and if there is a bootseq.yaml file in the current directory (or elsewhere, depending on a command-line flag).
High Availability considerations: This process runs only once. It is not concerned by high availability.
node-manager
Description: The stock node-manager offered here is to run a second nodeos instance when doing all-in-one deployments of a brand new chain. Its role is to run the instance that will produce nodes, distinct from the mindreader instance that will produce the data out of the execution of the produced blocks.
apiproxy
Description: The apiproxy is a small router to combine all dfuse services in a single HTTP(S) endpoint.
It is useful for eosq to have a single API to hit, for all the services, REST, WS and GraphQL, to avoid CORS issues. The apiproxy can be configured to route to those different services separately.
High Availability considerations: In larger deployments, you can use a pool of such processed, Kubernetes Ingress or other forms of load balancers to route external traffic to the right services. If you want to use it, you will want at least 2 to sustain one being down.
dashboard
Description: The dashboard is provided to observe what is happening with the different components. It gathers a few metrics from each process.
It will not work on larger deployments, as it needs to run in-process with the component (mindreader, reayer, etc.).
High Availability considerations: Not meant for HA deployments.
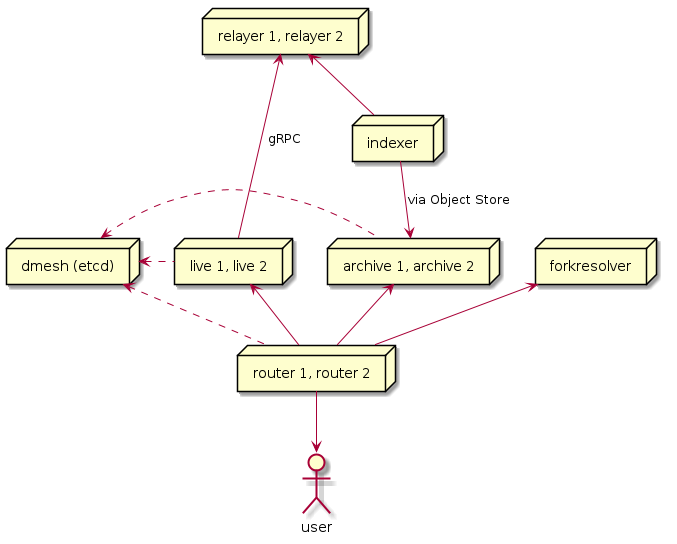
Search-Related Diagram
Search-Related Components Description
search-archive
Description: The archive backend of search stores only irreversible transactions. It can serve full history, or specific segments of the chain.
- It can listen to new indexes produces by a
search-indexer, automatically download and start serving them. This is called moving head. - It can also watch certain events to truncate the lower portion of the history it is serving, freeing some disk space and RAM usage. This is called moving tail.
- It can be useful to have several archives serving the same segment, with different indexes sizes, for resiliency purposes:
|<- Genesis --> history going forward --> HEAD -> |
| tier 1, 50,000 blocks indexes, moving head -----------------------------------------------------> |
| tier 2, 50 blks idx, moving tail/head |Since 50 blocks indexes are produced much quicker than 50,000 blocks indexes, this archive segment can be brought up much faster: you can parallelize production of a hundred 50 blks indexes, while you can’t parallelize the production of a 50,000 blocks
50,000 blocks indexes also have fixed boundaries, so you might be waiting for the last 1000 real-time blocks because you can finalize the 50,000 blocks index. Having 50 blocks indexes allows you to be much more reactive in case of issues.
The search-indexer can be instructed to only keep a certain moving window of indexes for a given tier, freeing up storage
High Availability considerations: To achieve high availability for any segment of the archive, you will need at least two copies.
search-indexer
Description: The search-indexer takes the stream of executed block data, and creates the bleve indexes. It then writes those indexes to a [dstore][https://github.com/dfuse-io/dstore] object store. The archive backend polls that object store for any newly produced indexes, downloads them and starts serving them.
It is configured with a given number of blocks per index. You can run multiple indexer, one for each index sizes.
Considerations for shard size (number of blocks in each index):
- The larger the index size, the longer it takes to process, and the longer you will wait on new live blocks before you can complete an index. Smaller indexes are more reactive in that sense.
Rule of thumb sizing:
- 50,000 blocks indexes for old segments, helps shrink the number of open files, and lower the overhead of an index.
- 5,000 blocks indexes for moving head segments, so you can relieve RAM pressure on the live nodes (which are waiting for purge their own memory once the
archivecovers their range). - 500 blocks indexes, similiar to the 5,000 blocks indexes, to lower the RAM requirements of
livenodes. - 50 blocks indexes to help being extremely reactive in case of dramatic events. Keep that for a short time window near the HEAD of the chain.
To keep indexes ranges coherent, we suggest they are multiples of 1, 2 or 5 and a power of ten (ex: 100, 2000, 50000, etc.).
The archive backend is able to query those indexes in parallel, ahead of time (spraying a given query on a large range of indexes, going faster and faster as it finds empty indexes). It is therefore possible to have 15,000 indexes under the same search-archive node. Be mindful of open-files in this situations, as each index will usually take 2 open files.
High-Availability considerations: search-indexer can be down for some time. archive nodes will not truncate their lower block range (when configured as moving tail) unless there is sufficient coverage of chain segments by lower tiers (archives that cover up to that block wanting to be truncated). Being down for a long time, will put pressure on disk space on those nodes with a moving tail configuration, but those nodes usually also have a moving head, and already have space reserved for growth.
search-live
Description: The live service of the search engine serves queries that concern the head of the chain.
It contains small 1-block indexes that are queried individually in the desired order to match backward and forward queries.
For forward queries, it also supports infinite querying (live querying), in which case it keeps the client connection open, indexes new blocks on-the-fly, applies queries and send any results, and then wait on the next block.
While doing so, it will navigate forks, re-applying queries on blocks detected to be forked, and return an “undo” result to the client.
The live nodes always contain at least the chain segments that are still reversible.
High Availability considerations: This service is stateless. On boot, it will fetch recent blocks from relayers, index them on the fly, prepare its representation of the current state of the head of the chain, and start serving requests. If you have lots of live queries going on, you will want to scale this one perhaps sooner than others. Make sure you have at least 2 to tolerate rolling updates or machine reboots.
search-forkresolver
Description: The forkresolver runs search queries on forked segments of the chain, when these happened a long time ago.
This service is called by the router in a very specific case:
- A user received results from the head of the chain, at that time, the blocks was not yet finalized (irreversible). The user therefore received a cursor containing the information of the exact block ID known to not be finalized. Call this a fork-aware cursor.
- That block ends up being forked out. The cursor would now be called a forked cursor.
- A request comes back, with a forked cursor, after a period of time long for that block height to have passed irreversibility (but with another block ID).
- The
livenodes have purged that block height from their memory as they noticed that thearchivenodes indexed it successfully. - In that case, the
routersends the request to theforkresolver, expecting it to search over just a few blocks that would connect back to what thearchivenodes are offering: irreversible data (or agreed upon blocks) - After getting the response from
forkresolver, therouterwill head to thearchiveand continue to search forward to reach the target block number (potentially hitting multiplearchivenodes, and then alivenode).
Another way to put it: archive nodes do not index forked blocks, so this process is there to safeguard the guarantees that the cursor will always be navigatable, even when passed irreversibility.
The forkresolver will pluck its data from the master source (merged blocks files), index on-the-fly only the segment that needs to be undone to reach the canonical and irreversible chain, apply the search query
NOTE: This requires that those merged blocks files still contain the originally forked cursor’s block. If you reprocess the chain (rerun mindreader and overwrite those merged block files), it is possible that you lose the information necessary to be able rejoin the canonical chain (the irreversible segment).
High Availability considerations: This is a stateless service. It needs to be up to service those types of queries (which are pretty rare). Put two for high availability.
search-router
Description: The router routes search queries to the different backends, depending on the block range being queried.
It will route searches that concern historical transactions to archive nodes. It will route forward forward searches into the future to the live backends. It will handling the passing of one backend to the next, when different backends don’t offer the full range queried.
The router discovers the state of
It can be configured to use a memcached server, that stores roaring bitmaps to accelerate
High Availability considerations: This process is stateless, and can be scaled up or down for the desired throughput. You want at least 2 to sustain one being down.
search-memcached
Description: Although not provided as an embedded service in dfuseeos, a memcached server can be configured on archive nodes of a search cluster to provide negative caching of queries. This means that indexes that yielded no results for a given query, will not be queried against when the same request comes again for the same index. In an archive setup where you have 1,000 indexes of 5,000 blocks each, this can dramatically increase performance.
High Availability considerations: Not having memcached will affect performances of queries that are done often, and over large block ranges.
search-etcd
Description: etcd is used as a the service discovery mechanism of the different components. It is the glue that ties routers to all the backends ready to serve certain requests.
It contains stateless data: if you trash the etcd cluster, all the components will simply go and write their latest state again, and things will be back up very fast.
Configure etcd with less than 1GB of storage, and with a short retention period, this way etcd will not outgrow its database and stay stable.
Reach out to https://etcd.io/docs/ for installation and deployment instructions.
If you are on Kubernetes, use the excellent https://github.com/coreos/etcd-operator and have it deployed in no time.
High Availability considerations: To sustain failures of the etcd cluster itself, deploy a small 1GB-sized 3-nodes cluster.